Aussie AI
Tokenizer Research
-
Last Updated 10 March, 2026
-
by David Spuler, Ph.D.
The tokenizer does not receive as much attention in the research literature as other parts of large language models. This is probably because the tokenization phase itself is not a bottleneck in either inference or training, when compared to the many layers of multiplication operations on weights. However, the choice of the tokenizer algorithm, and the resulting size of the vocabulary, has a direct impact on the speed (latency) of model inference.
Also, the tokenizer cannot be changed without re-training the model. The same tokenizer algorithm must be used in both training and inference, and the vocabulary is fixed. The only way that tokenization can be modified during inference is called "token pruning".
Tokenizer and Model Inference Latency
The tokenizer affects the latency (speed) of inference of a model in several ways. Firstly, the tokenization algorithm decides the vocabulary size. A larger vocabulary size directly affects the model's overall size (i.e. number of weights), and thereby has a big impact on the overall inference latency. If the tokenizer allows longer tokens, then there are more unique tokens, and the vocabulary is larger. For example, GPT has a vocabulary around 50,000 words (or subwords), but there are over 100,000 words in the English language, although they're not all in common usage.
Secondly, the tokenization method affects the ratio of words to tokens, which affects token sequence length for the input text. A longer sequence of tokens generated from the prompt text will cause longer latency in the inference phase. The transformer attention algorithm is known to be quadratic in input length, so fewer tokens reduce the overall processing. Furthermore, fewer tokens also helps reduce the cost of multiple model executions that arise from the "autoregression" problem, which is another LLM bottleneck.
Therefore, a tokenizer that uses individual words (longer) rather than subwords (shorter) will increase vocabulary size (increasing latency) but reduce input sequence (reducing latency). So the tokenization algorithm and the resulting size of the vocabulary introduces an interesting performance trade-off.
Tokenizer Design Issues
Some of the problematic design issues affecting tokenizers include:
- Numbers. There are an infinite number of numbers. Some tokenizers simply treat each digit as a separate token, whereas another approach is to treat common numbers (e.g. 100) as their own tokens, and use digits as tokens for other longer numbers.
- Capitalization. The tokenizer usually needs to distinguish capital letters, as it would otherwise make grammar errors with capitalization. But the need to represent both cases of letters increases the size of the vocabulary.
- Spaces. How should spaces be tokenized? One approach is that a space is its own token, separate from tokens for words (or numbers or punctuation). Another approach is that a space may be part of a subword sequence. And note that not all written languages use spaces to separate words like English does.
- Hyphenated words. Should these be 1 token or multiple?
- Contraction words. How should contractions with an apostrophe (e.g. "isn't") be tokenized?
- Punctuation characters and sequences. Usually a tokenizer will split punctuation characters into a single-byte token. But there are various multi-character punctuation sequences that could be their own token.
- Encoding. Will the input sequence be in Latin1 or UTF8 encoding? Or various others like double-byte Unicode. The model will become confused if it was trained on one encoding, but receives input tokenized from another encoding during inference.
- UTF8 and Unicode characters. The vast number of standard byte encodings for obscure symbols makes life difficult for tokenizers. One approach is to ignore this, and simply have a token for each byte that's not part of a known word or other token (i.e. a maximum of 255 of these byte-level tokens).
- Double-byte character set languages. Several languages such as Chinese and Japanese have a large number of distinct symbols, which increases the size of the tokenizer and its vocabulary.
- European language letters. Even the relatively simple ASCII extensions with values 128..255 to support European letters need to be handled correctly. Note that there are actually more than 255, so a multi-byte sequence such as UTF8 is probably desirable. However, if using UTF8, should the common European letters get their own token for byte-pairs or byte-triples?
- Escape codes. There are various non-printable escape sequences defined by ASCII. Some encodings have meanings for these, but in other encodings they are undefined. An example is ASCII byte code 127, and also various bytes in the range 1-32.
- Encoding errors. If using UTF8, there are various byte sequences that are errors that don't properly encode any Unicode number. What should the tokenizer do in this case?
- Null bytes. Should the tokenizer allow zero as a token? This is mainly relevant to binary file tokenization.
- Computer programming language tokens. Each major programming language has its own specific set of tokens. Should the LLM tokenizer use these tokens or not?
- Programming language sequences. Should the tokenizer have separate individual tokens for multi-character tokens (even in Latin1 encoding), such as HTML macros (e.g. bold) and HTML entities (e.g. em dash).
- Unknown tokens. The tokenizer must not produce any tokens that the model doesn't know. Otherwise, there's unpredictable behavior during model inference.
- Rare words. How should an unknown word be tokenized? By subwords or syllables? By letters?
- End-of-input token. The tokenizer needs a way to identify the end of the input stream. This can be implemented via a unique marker token, although there are other ways.
- Semantic tokenization and parts of speech. Should the tokenizer attempt to discern some meaning from the words? For example, should it try to distinguish the same word as a different part of speech, such as a different token for a word as a noun or a verb? Or should the tokenizer leave that issue for the model to decide? This is a newer area of research.
Tokenizer Algorithms
Some of the existing tokenizer algorithms include:
- Single characters/bytes (early models)
- Byte-Pair Encoding (BPE), from Gage (1994), is a longstanding method.
- WordPiece, from Wu et al. (2016) uses subword tokenization and Google has open-sourced the code.
- SentencePiece, Kudo and Richardson (2018), with an open-source codebase from Google, as used by LLama.
- Unigram (Kudo, 2018)
Research on Tokenization
Tokenizers are often barely mentioned in AI papers, but there are some research papers specifically on the design of tokenization algorithms:
- Sandeep Mehta, Darpan Shah, Ravindra Kulkarni, Cornelia Caragea, Semantic Tokenizer for Enhanced Natural Language Processing, Apr 2023, https://arxiv.org/abs/2304.12404
- Sanghyun Choo & Wonjoon Kim, A study on the evaluation of tokenizer performance in natural language processing, Feb 2023, https://doi.org/10.1080/08839514.2023.2175112
- SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing Taku Kudo, John Richardson, Aug 2018, https://arxiv.org/abs/1808.06226, Code: https://github.com/google/sentencepiece
- Jasdeep Singh, Bryan McCann, Richard Socher, Caiming Xiong, BERT is Not an Interlingua and the Bias of Tokenization, Proceedings of the 2nd Workshop on Deep Learning Approaches for Low-Resource NLP (DeepLo 2019), November 2019, https://aclanthology.org/D19-6106/
- Xinying Song, Alex Salcianu, Yang Song, Dave Dopson, Denny Zhou, Fast WordPiece Tokenization, Dec 2020, https://arxiv.org/abs/2012.15524
- Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et al. 2016. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144, https://arxiv.org/abs/1609.08144 (WordPiece tokenizer seminal paper)
- Mike Schuster and Kaisuke Nakajima, 2012, Japanese and korean voice search, In Proc. of ICASSP, 2012, https://ieeexplore.ieee.org/document/6289079 (Byte-Pair-Encoding for Asian languages)
- Rico Sennrich, Barry Haddow, and Alexandra Birch, 2016, Neural machine translation of rare words with subword units, In Proc. of ACL. https://arxiv.org/abs/1508.07909
- Taku Kudo, Subword regularization: Improving neural network translation models with multiple subword candidates, In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 66–75, Melbourne, Australia, July 2018, Association for Computational Linguistics, https://arxiv.org/abs/1804.10959
- Philip Gage, 1994, A New Algorithm for Data Compression. C Users J., 12(2):23–38, February 1994, PDF: https://www.derczynski.com/papers/archive/BPE_Gage.pdf (Byte-Pair Encoding early paper)
- Jonathan J. Webster, Chunyu Kit, Tokenization as the initial phase in NLP, 1992, COLING '92: Proceedings of the 14th conference on Computational linguistics, Volume 4, August 1992, pp.1106–1110, https://doi.org/10.3115/992424.992434 PDF: https://aclanthology.org/C92-4173.pdf (early research on tokenization)
- Finding the Optimal Vocabulary Size for Neural Machine Translation, Thamme Gowda and Jonathan May, Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3955–3964, November 16-20, 2020, PDF: https://aclanthology.org/2020.findings-emnlp.352.pdf
- Christopher D. Manning, Mihai Surdeanu, John Bauer, Jenny Finkel, Steven J. Bethard, and David McClosky. 2014. The Stanford CoreNLP natural language processing toolkit. In Association for Computational Linguistics (ACL) System Demonstrations, pages 55–60. https://aclanthology.org/P14-5010/ PDF: https://nlp.stanford.edu/pubs/StanfordCoreNlp2014.pdf
- On the Role of Text Preprocessing in Neural Network Architectures: An Evaluation Study on Text Categorization and Sentiment Analysis, Jose Camacho-Collados, Mohammad Taher Pilehvar, July 2017, https://arxiv.org/abs/1707.01780
- Y. Tay, V. Q. Tran, S. Ruder, J. Gupta, H. W. Chung, D. Bahri, Z. Qin, S. Baumgartner, C. Yu, and D. Metzler, Charformer: Fast character transformers via gradient-based subword tokenization, arXiv preprint arXiv:2106.12672, 2021. https://arxiv.org/abs/2106.12672
- Challenges and Applications of Large Language Models, Jean Kaddour, Joshua Harris, Maximilian Mozes, Herbie Bradley, Roberta Raileanu, Robert McHardy, July 2023, https://arxiv.org/pdf/2307.10169.pdf (General LLM survey that contains some discussion of tokenization.)
- David D. Palmer, 2000, Tokenisation and sentence segmentation, In Robert Dale, Hermann Moisl, and Harold Somers, editors, Handbook of Natural Language Processing, Chapter 2, pages 24–25. Marcel Dekker. https://www.semanticscholar.org/paper/Chapter-2-%3A-Tokenisation-and-Sentence-Segmentation-Palmer/eeb93adb89f0621fd13c8701b40eaeae74e0c804 , PDF: https://tm-town-nlp-resources.s3.amazonaws.com/ch2.pdf
- Stanford, Tokenization & Sentence Segmentation, https://stanfordnlp.github.io/stanza/tokenize.html
- Thomas Reps. 1998. “Maximal-Munch” Tokenization in Linear Time. ACM Trans. Program. Lang. Syst., 20(2):259–273. https://dl.acm.org/doi/10.1145/276393.276394, DOI: https://doi.org/10.1145/276393.276394 (Tokenization in linear time.)
- HuggingFace. 2020. Tokenizers. https://github.com/huggingface/tokenizers
- Jonathan J. Webster and Chunyu Kit. 1992. Tokenization as the initial phase in NLP. In COLING 1992 Volume 4: The 14th International Conference on Computational Linguistics, https://dl.acm.org/doi/10.3115/992424.992434, DOI: https://doi.org/10.3115/992424.992434
- Google. 2018. The WordPiece Algorithm in Open Source BERT. Code: https://github.com/google-research/bert/blob/master/tokenization.py#L335-L358 -> tokenizer
- Christopher D. Manning, Mihai Surdeanu, John Bauer, Jenny Finkel, Steven J. Bethard, and David McClosky. 2014. The Stanford CoreNLP natural language processing toolkit. In Association for Computational Linguistics (ACL) System Demonstrations, pages 55–60. https://aclanthology.org/P14-5010/, PDF: https://nlp.stanford.edu/pubs/StanfordCoreNlp2014.pdf
- Dan Klein and Christopher D. Manning. 2003. Fast exact inference with a factored model for natural language parsing. In Suzanna Becker, Sebastian Thrun, and Klaus Obermayer, editors, Advances in Neural Information Processing Systems, volume 15, pages 3–10. MIT Press, PDF: https://nlp.stanford.edu/~manning/papers/lex-parser.pdf
- Marie-Catherine de Marneffe, Bill MacCartney, and Christopher D. Manning. 2006. Generating typed dependency parses from phrase structure parses. In LREC 2006, pages 449–454, PDF: http://www.lrec-conf.org/proceedings/lrec2006/pdf/440_pdf.pdf
- Kristina Toutanova, Dan Klein, Christopher D. Manning, and Yoram Singer. 2003. Feature-rich part-of-speech tagging with a cyclic dependency network. In NAACL 3, pages 252–259, https://dl.acm.org/doi/10.3115/1073445.1073478
- How Much Does Tokenization Affect Neural Machine Translation? Miguel Domingo, Mercedes García-Martínez, Alexandre Helle, Francisco Casacuberta & Manuel Herranz, LNCS, volume 13451, CICLing 2019: Computational Linguistics and Intelligent Text Processing, pp 545–554, https://link.springer.com/chapter/10.1007/978-3-031-24337-0_38, https://arxiv.org/abs/1812.08621
- C. Gong, D. He, X. Tan, T. Qin, L. Wang, and T.-Y. Liu, “Frage: Frequency-agnostic word representation,” in NeurIPS, 2018, https://arxiv.org/abs/1809.06858
- Y. Tay, V. Q. Tran, S. Ruder, J. Gupta, H. W. Chung, D. Bahri, Z. Qin, S. Baumgartner, C. Yu, and D. Metzler, June 2021, Charformer: Fast character transformers via gradient-based subword tokenization, arXiv preprint arXiv:2106.12672, 2021. https://arxiv.org/abs/2106.12672 (CharacterBERT)
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics. https://arxiv.org/abs/1810.04805 (uses WordPiece tokenizer)
- Ye Lin, Yanyang Li, Tong Xiao, Jingbo Zhu, Bag of Tricks for Optimizing Transformer Efficiency, Findings of the Association for Computational Linguistics: EMNLP 2021, November 2021, https://aclanthology.org/2021.findings-emnlp.357/
- Yoon Kim, Yacine Jernite, David A. Sontag, and Alexander M. Rush. Character-aware neural language models. In AAAI, pp. 2741–2749. AAAI Press, 2016.
- Jonas Geiping, Tom Goldstein, Dec 2022, Cramming: Training a Language Model on a Single GPU in One Day, https://arxiv.org/abs/2212.14034, Code: https://github.com/JonasGeiping/cramming (Examines the impact of tokenizers WordPiece and BPE, and also separator tokens, on training efficiency. Note: code uses deprecated nvFuser compiler.)
- Alibaba Qwen Team, Sep 2023, Qwen Technical Report, https://arxiv.org/pdf/2309.16609.pdf (Has a section on tokenizer implementation.)
- Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. PaLM: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022. https://arxiv.org/abs/2204.02311 (Google Palm architecture tokenizer split unknown Unicode tokens into UTF8, with a separate token for each UTF8 byte. Also uses a token for each numeric digit, splitting numbers into multiple tokens.)
- Benjamin Minixhofer, Edoardo Maria Ponti, Ivan Vulić, 13 May 2024, Zero-Shot Tokenizer Transfer, https://arxiv.org/abs/2405.07883 (Overcoming the limitation that the tokenizer is fixed for the model, by training the tokenizer to embeddings mapping so as to use different tokenizers, including effective input token pruning reducing tokens in the input with a larger vocabulary.)
- Kevin Slagle, 22 Apr 2024, SpaceByte: Towards Deleting Tokenization from Large Language Modeling, https://arxiv.org/abs/2404.14408
- Jesus Rodriguez, Apr 22, 2024, Some Technical Notes About Llama 3: New tokenizer, optimized pretraining and some other details about Meta AI’s new model, Towards AI, https://pub.towardsai.net/some-technical-notes-about-llama-3-042c0b19db14
- Sachin Mehta, Mohammad Hossein Sekhavat, Qingqing Cao, Maxwell Horton, Yanzi Jin, Chenfan Sun, Iman Mirzadeh, Mahyar Najibi, Dmitry Belenko, Peter Zatloukal, Mohammad Rastegari, 22 Apr 2024, OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework, Apple Research, https://arxiv.org/abs/2404.14619 Code: https://huggingface.co/apple/OpenELM
- Yoon Kim, Yacine Jernite, David A. Sontag, and Alexander M. Rush. 2016. Character-aware neural language models. In AAAI, pp. 2741–2749. AAAI Press, 2016, https://arxiv.org/abs/1508.06615
- Yehui Tang, Yunhe Wang, Jianyuan Guo, Zhijun Tu, Kai Han, Hailin Hu, Dacheng Tao, 5 Feb 2024. A Survey on Transformer Compression. https://arxiv.org/abs/2402.05964 (Model compression survey paper with focus on pruning, quantization, knowledge distillation, and efficient architecture design.)
- Andrej Karpathy, 2023, Let's build the GPT Tokenizer, https://www.youtube.com/watch?v=zduSFxRajkE
- Nikolay Bogoychev, Pinzhen Chen, Barry Haddow, Alexandra Birch, Nov 2023, Large Language Model Inference with Lexical Shortlisting, https://arxiv.org/abs/2311.09709 (Shortlisting the vocabulary to common words for reduced tokens and embedding matrix size.)
- David Spuler, March 2024, Chapter 27. Tokenizer and Vocabulary, Generative AI in C++: Coding Transformers and LLMs, https://www.amazon.com/dp/B0CXJKCWX9
- Hugging Face, January 18, 2021, How we sped up transformer inference 100x for HF API customers, https://huggingface.co/blog/accelerated-inference
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin, Attention is all you need, 2017, arXive preprint arXiv:1706.03762. https://arxiv.org/abs/1706.03762
- Adaptive Input Representations for Neural Language Modeling, Alexei Baevski, Michael Auli, Feb 2019, https://arxiv.org/abs/1809.10853
- Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. https://arxiv.org/abs/2302.13971
- Ori Ram, Liat Bezalel, Adi Zicher, Yonatan Belinkov, Jonathan Berant, and Amir Globerson. 2022. What are you token about? dense retrieval as distributions over the vocabulary. arXiv preprint arXiv:2212.10380 https://arxiv.org/abs/2212.10380
- J Mu, XL Li, N Goodman, 2023, Learning to compress prompts with gist tokens, https://arxiv.org/abs/2304.08467
- NVIDIA, June 2024, Nemotron-4 340B Technical Report, https://d1qx31qr3h6wln.cloudfront.net/publications/Nemotron_4_340B_8T_0.pdf (Architecture is decoder-only with GQA, SentencePiece tokenizer, causal attention masks, RoPE, 96 layers, 96 heads, 8 KV heads, 256,000 vocabulary, 18432 internal dimension, context window 4096, and uses squared RELU.)
- Björn Deiseroth, Manuel Brack, Patrick Schramowski, Kristian Kersting, Samuel Weinbach, 27 Jun 2024, T-FREE: Tokenizer-Free Generative LLMs via Sparse Representations for Memory-Efficient Embeddings, https://arxiv.org/abs/2406.19223
- Yuqing Yang, Yuedong Xu, Lei Jiao, 7 Jul 2024, A Queueing Theoretic Perspective on Low-Latency LLM Inference with Variable Token Length, https://arxiv.org/abs/2407.05347
- An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfeng Xue, Na Ni, Pei Zhang, Peng Wang, Ru Peng, Rui Men, Ruize Gao, Runji Lin, Shijie Wang, Shuai Bai, Sinan Tan, Tianhang Zhu, Tianhao Li, Tianyu Liu, Wenbin Ge, Xiaodong Deng, Xiaohuan Zhou, Xingzhang Ren, Xinyu Zhang, Xipin Wei, Xuancheng Ren, Yang Fan, Yang Yao, Yichang Zhang, Yu Wan, Yunfei Chu, Zeyu Cui, Zhenru Zhang, Zhihao Fan, 15 Jul 2024, Qwen2 Technical Report, https://arxiv.org/abs/2407.10671
- Chaofan Tao, Qian Liu, Longxu Dou, Niklas Muennighoff, Zhongwei Wan, Ping Luo, Min Lin, Ngai Wong, 18 Jul 2024, Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies, https://arxiv.org/abs/2407.13623
- Aleksandar Petrov, Emanuele La Malfa, Philip H.S. Torr, Adel Bibi, 20 Oct 2023 (v2), Language Model Tokenizers Introduce Unfairness Between Languages, https://arxiv.org/pdf/2305.15425
- Orevaoghene Ahia, Sachin Kumar, Hila Gonen, JungoKasai, David R. Mortensen, Noah A. Smith, Yulia Tsvetkov, 2024, Do All Languages Cost the Same? Tokenization in the Era of Commercial Language Models, https://openreview.net/pdf?id=OUmxBN45Gl
- Yennie Jun, May 03, 2023, All languages are NOT created (tokenized) equal: Language models cost much more in some languages than others, https://www.artfish.ai/p/all-languages-are-not-created-tokenized
- Dimitris Spathis, Fahim Kawsar, The first step is the hardest: pitfalls of representing and tokenizing temporal data for large language models, Journal of the American Medical Informatics Association, Volume 31, Issue 9, September 2024, Pages 2151–2158, https://doi.org/10.1093/jamia/ocae090 https://academic.oup.com/jamia/advance-article-abstract/doi/10.1093/jamia/ocae090/7702405?redirectedFrom=fulltext
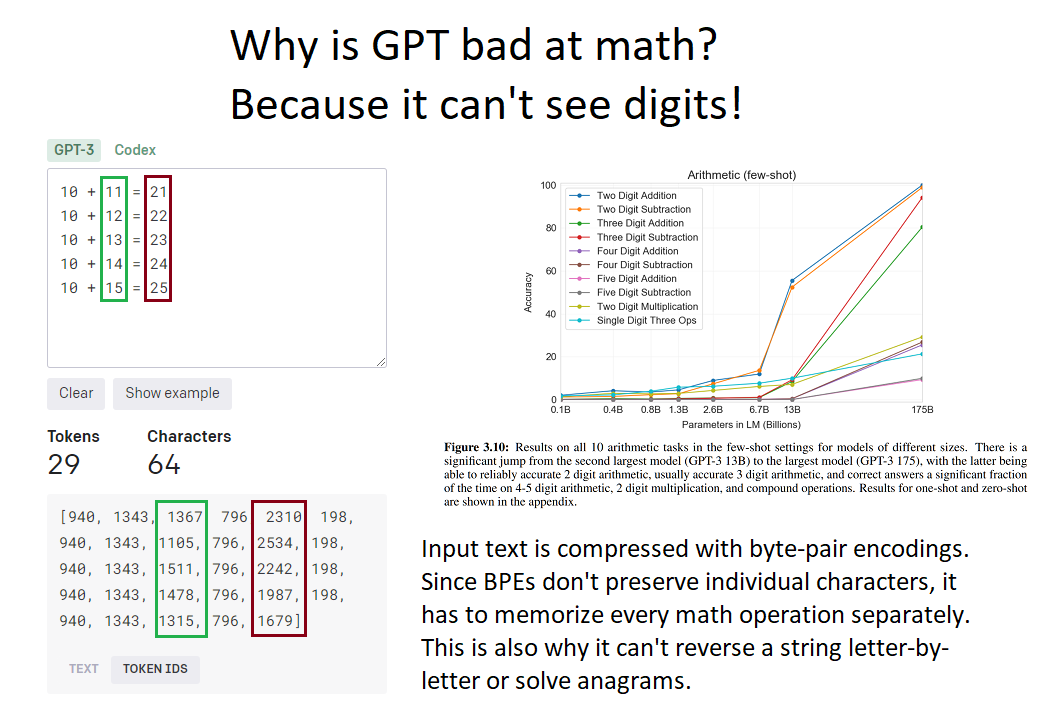
- Bbot, 2024, Why is GPT bad at math? Because it can't see digits! https://bbot.org/etc/gpt-math.png
- McKinsey, July 25, 2024, What is tokenization? https://www.mckinsey.com/featured-insights/mckinsey-explainers/what-is-tokenization
- Cybernetist, Oct 2024, You Should Probably Pay Attention to Tokenizers, https://cybernetist.com/2024/10/21/you-should-probably-pay-attention-to-tokenizers/
- Shenghao Xie, Wenqiang Zu, Mingyang Zhao, Duo Su, Shilong Liu, Ruohua Shi, Guoqi Li, Shanghang Zhang, Lei Ma, 30 Oct 2024 (v2), Towards Unifying Understanding and Generation in the Era of Vision Foundation Models: A Survey from the Autoregression Perspective, https://arxiv.org/abs/2410.22217 https://github.com/EmmaSRH/ARVFM
- Sebastian Raschka, Nov 03, 2024, Understanding Multimodal LLMs: An introduction to the main techniques and latest models, https://magazine.sebastianraschka.com/p/understanding-multimodal-llms
- NVIDIA, Nov 2024, Cosmos Tokenizer: A suite of image and video neural tokenizers, https://research.nvidia.com/labs/dir/cosmos-tokenizer/
- Ziqi Pang, Tianyuan Zhang, Fujun Luan, Yunze Man, Hao Tan, Kai Zhang, William T. Freeman, Yu-Xiong Wang, 2 Dec 2024, RandAR: Decoder-only Autoregressive Visual Generation in Random Orders, https://arxiv.org/abs/2412.01827 https://rand-ar.github.io/ (Attempt to parallelize image generation decoding by randomizing the order at which to create patches of an image.)
- J Hong, G Lee, J Cho, Accelerating Multilingual Language Model for Excessively Tokenized Languages, Findings of the Association for Computational Linguistics: ACL 2024, pages 11095–11111 August 11-16, 2024, https://arxiv.org/abs/2401.10660 https://aclanthology.org/2024.findings-acl.660/ https://aclanthology.org/2024.findings-acl.660.pdf
- Artidoro Pagnoni, Ram Pasunuru, Pedro Rodriguez, John Nguyen, Benjamin Muller, Margaret Li, Chunting Zhou, Lili Yu, Jason Weston, Luke Zettlemoyer, Gargi Ghosh, Mike Lewis, Ari Holtzman, Srini Iyer, Dec 2024, Byte Latent Transformer: Patches Scale Better Than Tokens, Meta, https://ai.meta.com/research/publications/byte-latent-transformer-patches-scale-better-than-tokens/
- Yipeng Zhang, Yifan Liu, Zonghao Guo, Yidan Zhang, Xuesong Yang, Chi Chen, Jun Song, Bo Zheng, Yuan Yao, Zhiyuan Liu, Tat-Seng Chua, Maosong Sun, 18 Dec 2024, LLaVA-UHD v2: an MLLM Integrating High-Resolution Feature Pyramid via Hierarchical Window Transformer, https://arxiv.org/abs/2412.13871
- Qwen: An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu Xia, Xingzhang Ren, Xuancheng Ren, Yang Fan, Yang Su, Yichang Zhang, Yu Wan, Yuqiong Liu, Zeyu Cui, Zhenru Zhang, Zihan Qiu (additional authors not shown), 19 Dec 2024, Qwen2.5 Technical Report, https://arxiv.org/abs/2412.15115
- Seungdong Yoa, Seungjun Lee, Hyeseung Cho, Bumsoo Kim, Woohyung Lim, 21 Dec 2024, ImagePiece: Content-aware Re-tokenization for Efficient Image Recognition, https://arxiv.org/abs/2412.16491
- Aaditya K. Singh, DJ Strouse, 22 Feb 2024, Tokenization counts: the impact of tokenization on arithmetic in frontier LLMs, https://arxiv.org/abs/2402.14903
- Andrea Matarazzo, Riccardo Torlone, 3 Jan 2025, A Survey on Large Language Models with some Insights on their Capabilities and Limitations, https://arxiv.org/abs/2501.04040 (Broad survey with many LLM topics covered from history to architectures to optimizations.)
- Asif Razzaq, January 22, 2025, Meet EvaByte: An Open-Source 6.5B State-of-the-Art Tokenizer-Free Language Model Powered by EVA, https://www.marktechpost.com/2025/01/22/meet-evabyte-an-open-source-6-5b-state-of-the-art-tokenizer-free-language-model-powered-by-eva/
- Anna Wegmann, Dong Nguyen, David Jurgens, 21 Feb 2025, Tokenization is Sensitive to Language Variation, https://arxiv.org/abs/2502.15343 (Examines issues such as British versus American spelling.)
- Xinsheng Wang, Mingqi Jiang, Ziyang Ma, Ziyu Zhang, Songxiang Liu, Linqin Li, Zheng Liang, Qixi Zheng, Rui Wang, Xiaoqin Feng, Weizhen Bian, Zhen Ye, Sitong Cheng, Ruibin Yuan, Zhixian Zhao, Xinfa Zhu, Jiahao Pan, Liumeng Xue, Pengcheng Zhu, Yunlin Chen, Zhifei Li, Xie Chen, Lei Xie, Yike Guo, Wei Xue, 3 Mar 2025, Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens, https://arxiv.org/abs/2503.01710 https://github.com/SparkAudio/Spark-TTS
- Haichao Zhang, Yun Fu, 30 Mar 2025 (v2), Token Dynamics: Towards Efficient and Dynamic Video Token Representation for Video Large Language Models, https://arxiv.org/abs/2503.16980
- Lavanya Gupta, May 1, 2025, Hidden costs in AI deployment: Why Claude models may be 20-30% more expensive than GPT in enterprise settings, https://venturebeat.com/ai/hidden-costs-in-ai-deployment-why-claude-models-may-be-20-30-more-expensive-than-gpt-in-enterprise-settings/ (The Claude tokenizer apparently creates more tokens than GPT.)
- lucalp, 24/06/2025, The Bitter Lesson is coming for Tokenization: a world of LLMs without tokenization is desirable and increasingly possible, https://lucalp.dev/bitter-lesson-tokenization-and-blt/
- GPT-5 Blog, June 30th, 2025, Show HN: TokenDagger – A tokenizer faster than OpenAI's Tiktoken, https://www.gpt-5.com/89212294/show-hn-tokendagger-a-tokenizer-faster-than-openais-tiktoken https://github.com/M4THYOU/TokenDagger
- Mathurin Videau, Badr Youbi Idrissi, Alessandro Leite, Marc Schoenauer, Olivier Teytaud, David Lopez-Paz, 17 Jun 2025, From Bytes to Ideas: Language Modeling with Autoregressive U-Nets, https://arxiv.org/abs/2506.14761
- Hao Wang, Yu Liu, Daniel Biggs, Haoru Wang, Jiandong Yu, Ping Huang, 18 Jul 2025, Learning Deformable Body Interactions With Adaptive Spatial Tokenization, https://arxiv.org/abs/2507.13707
- Haoyu He, Haozheng Luo, Yan Chen, Qi R. Wang, 18 Jul 2025, Efficient Temporal Tokenization for Mobility Prediction with Large Language Models, https://arxiv.org/abs/2507.14017
- Luyi Ma, Wanjia Zhang, Kai Zhao, Abhishek Kulkarni, Lalitesh Morishetti, Anjana Ganesh, Ashish Ranjan, Aashika Padmanabhan, Jianpeng Xu, Jason Cho, Praveen Kanumala, Kaushiki Nag, Sumit Dutta, Kamiya Motwani, Malay Patel, Evren Korpeoglu, Sushant Kumar, Kannan Achan, 19 Jul 2025, GRACE: Generative Recommendation via Journey-Aware Sparse Attention on Chain-of-Thought Tokenization, https://arxiv.org/abs/2507.14758
- Boris Ivanovic, Cristiano Saltori, Yurong You, Yan Wang, Wenjie Luo, Marco Pavone, 21 Jul 2025, Efficient Multi-Camera Tokenization with Triplanes for End-to-End Driving, https://arxiv.org/abs/2506.12251
- Jindong Li, Yali Fu, Jiahong Liu, Linxiao Cao, Wei Ji, Menglin Yang, Irwin King, Ming-Hsuan Yang, 21 Jul 2025, Discrete Tokenization for Multimodal LLMs: A Comprehensive Survey, https://arxiv.org/abs/2507.22920
- Negar Foroutan, Clara Meister, Debjit Paul, Joel Niklaus, Sina Ahmadi, Antoine Bosselut, Rico Sennrich, 6 Aug 2025, Parity-Aware Byte-Pair Encoding: Improving Cross-lingual Fairness in Tokenization, https://arxiv.org/abs/2508.04796
- Adit Krishnan, Chu Wang, Chris Kong, 12 Aug 2025, Classifier Language Models: Unifying Sparse Finetuning and Adaptive Tokenization for Specialized Classification Tasks, https://arxiv.org/abs/2508.08635
- Saketh Reddy Vemula, Dipti Mishra Sharma and Parameswari Krishnamurthy, 11 Aug 2025, Rethinking Tokenization for Rich Morphology: The Dominance of Unigram over BPE and Morphological Alignment, https://arxiv.org/abs/2508.08424
- Liping Huang, Yicheng Zhang, Yifang Yin, Sheng Zhang, Yi Zhang, 31 Jul 2025, Efficient Real-Time Aircraft ETA Prediction via Feature Tokenization Transformer, https://arxiv.org/abs/2508.09144
- Hermione Warr, Wentian Xu, Harry Anthony, Yasin Ibrahim, Daniel McGowan, Konstantinos Kamnitsas, 13 Aug 2025, Specialised or Generic? Tokenization Choices for Radiology Language Models, https://arxiv.org/abs/2508.09952
- Haohao Qu, Wenqi Fan, Zihuai Zhao, Qing Li, 15 Aug 2025, TokenRec: Learning to Tokenize ID for LLM-based Generative Recommendation, https://arxiv.org/abs/2406.10450
- Andrei-Valentin T\u{a}nase, Elena Pelican, 16 Aug 2025, SupraTok: Cross-Boundary Tokenization for Enhanced Language Model Performance, https://arxiv.org/abs/2508.11857
- Jinning Yang and Wen Shi, 21 Aug 2025, DiagECG: An LLM-Driven Framework for Diagnostic Reasoning via Discretized ECG Tokenization, https://arxiv.org/abs/2508.15338
- Dong Liu, Yanxuan Yu, 21 Aug 2025, SemToken: Semantic-Aware Tokenization for Efficient Long-Context Language Modeling, https://arxiv.org/abs/2508.15190
- Simon Lepage, Jeremie Mary, David Picard, 12 Aug 2025, Closing the Performance Gap in Generative Recommenders with Collaborative Tokenization and Efficient Modeling, https://arxiv.org/abs/2508.14910
- Yi Xu, Moyu Zhang, Chenxuan Li, Zhihao Liao, Haibo Xing, Hao Deng, Jinxin Hu, Yu Zhang, Xiaoyi Zeng, Jing Zhang, 21 Aug 2025, MMQ: Multimodal Mixture-of-Quantization Tokenization for Semantic ID Generation and User Behavioral Adaptation, https://arxiv.org/abs/2508.15281
- Seojin Kim, Hyeontae Song, Jaehyun Nam, Jinwoo Shin, 30 Aug 2025, Training Text-to-Molecule Models with Context-Aware Tokenization, https://arxiv.org/abs/2509.04476
- Jessica M. Lundin, Ada Zhang, Nihal Karim, Hamza Louzan, Victor Wei, David Adelani, Cody Carroll, 5 Sep 2025, The Token Tax: Systematic Bias in Multilingual Tokenization, https://arxiv.org/abs/2509.05486
- Ander Artola Velasco, Stratis Tsirtsis, Nastaran Okati, Manuel Gomez-Rodriguez, 9 Sep 2025, Is Your LLM Overcharging You? Tokenization, Transparency, and Incentives, https://arxiv.org/abs/2505.21627
- Haichao Zhang, Wenhao Chai, Shwai He, Ang Li, Yun Fu, 18 Sep 2025, Dense Video Understanding with Gated Residual Tokenization, https://arxiv.org/abs/2509.14199
- Linus Kreitner, Paul Hager, Jonathan Mengedoht, Georgios Kaissis, Daniel Rueckert, Martin J. Menten, 8 Oct 2025, Efficient numeracy in language models through single-token number embeddings, https://arxiv.org/abs/2510.06824 (Looking at tokenization of numbers and digits.)
- Craig W. Schmidt, Varshini Reddy, Chris Tanner, Yuval Pinter, 2 Oct 2025, Boundless Byte Pair Encoding: Breaking the Pre-tokenization Barrier, https://arxiv.org/abs/2504.00178
- Hailay Kidu Teklehaymanot, Wolfgang Nejdl, 14 Oct 2025, Tokenization Disparities as Infrastructure Bias: How Subword Systems Create Inequities in LLM Access and Efficiency, https://arxiv.org/abs/2510.12389
- Vani Kanjirangat, Tanja Samard\v{z}i\'c, Ljiljana Dolamic, Fabio Rinaldi, 24 Sep 2025, Tokenization and Representation Biases in Multilingual Models on Dialectal NLP Tasks, https://arxiv.org/abs/2509.20045
- Gagan Bhatia, Maxime Peyrard, Wei Zhao, 24 Sep 2025, Date Fragments: A Hidden Bottleneck of Tokenization for Temporal Reasoning, https://arxiv.org/abs/2505.16088
- Jingyue Huang and Zachary Novack and Phillip Long and Yupeng Hou and Ke Chen and Taylor Berg-Kirkpatrick and Julian McAuley, 18 Oct 2025, MuseTok: Symbolic Music Tokenization for Generation and Semantic Understanding, https://arxiv.org/abs/2510.16273
- Haoyu He, Haozheng Luo, Yan Chen, Qi R. Wang, 20 Oct 2025, RHYTHM: Reasoning with Hierarchical Temporal Tokenization for Human Mobility, https://arxiv.org/abs/2509.23115
- Kai Zhuang, Jiawei Zhang, Yumou Liu, Hanqun Cao, Chunbin Gu, Mengdi Liu, Zhangyang Gao, Zitong Jerry Wang, Xuanhe Zhou, Pheng-Ann Heng, Lijun Wu, Conghui He, Cheng Tan, 27 Oct 2025, Lost in Tokenization: Context as the Key to Unlocking Biomolecular Understanding in Scientific LLMs, https://arxiv.org/abs/2510.23127
- Pritish Chakraborty, Indradyumna Roy, Soumen Chakrabarti, Abir De, 26 Oct 2025, Contextual Tokenization for Graph Inverted Indices, https://arxiv.org/abs/2510.22479
- Mir Tafseer Nayeem, Sawsan Alqahtani, Md Tahmid Rahman Laskar, Tasnim Mohiuddin, M Saiful Bari, 26 Oct 2025, Beyond Fertility: Analyzing STRR as a Metric for Multilingual Tokenization Evaluation, https://arxiv.org/abs/2510.09947
- Konstantinos Barmpas, Na Lee, Alexandros Koliousis, Yannis Panagakis, Dimitrios A. Adamos, Nikolaos Laskaris, Stefanos Zafeiriou, 15 Oct 2025, NeuroRVQ: Multi-Scale EEG Tokenization for Generative Large Brainwave Models, https://arxiv.org/abs/2510.13068
- Jeff Shen, Francois Lanusse, Liam Holden Parker, Ollie Liu, Tom Hehir, Leopoldo Sarra, Lucas Meyer, Micah Bowles, Sebastian Wagner-Carena, Sebastian Wagner-Carena, Helen Qu, Siavash Golkar, Alberto Bietti, Hatim Bourfoune, Nathan Cassereau, Pierre Cornette, Keiya Hirashima, Geraud Krawezik, Ruben Ohana, Nicholas Lourie, Michael McCabe, Rudy Morel, Payel Mukhopadhyay, Mariel Pettee, Bruno R\'egaldo-Saint Blancard, Kyunghyun Cho, Miles Cranmer, Shirley Ho, 20 Oct 2025, Universal Spectral Tokenization via Self-Supervised Panchromatic Representation Learning, https://arxiv.org/abs/2510.17959
- Ruiyu Wang, Shizhao Sun, Weijian Ma, Jiang Bian, 25 Sep 2025, CAD-Tokenizer: Towards Text-based CAD Prototyping via Modality-Specific Tokenization, https://arxiv.org/abs/2509.21150
- Moshe Kimhi, Erez Koifman, Ehud Rivlin, Eli Schwartz, Chaim Baskin, 25 Sep 2025, WAVECLIP: Wavelet Tokenization for Adaptive-Resolution CLIP, https://arxiv.org/abs/2509.21153
- Rokas Bendikas, Daniel Dijkman, Markus Peschl, Sanjay Haresh, Pietro Mazzaglia, 28 Sep 2025, Focusing on What Matters: Object-Agent-centric Tokenization for Vision Language Action models, https://arxiv.org/abs/2509.23655
- Md Mubtasim Ahasan, Md Fahim, Tasnim Mohiuddin, A K M Mahbubur Rahman, Aman Chadha, Tariq Iqbal, M Ashraful Amin, Md Mofijul Islam, Amin Ahsan Ali, 29 Sep 2025, DM-Codec: Distilling Multimodal Representations for Speech Tokenization, https://arxiv.org/abs/2410.15017
- Jia Peng Lim, Shawn Tan, Davin Choo, Hady W. Lauw, 28 Sep 2025, A Partition Cover Approach to Tokenization, https://arxiv.org/abs/2501.06246
- Saibo Geng, Nathan Ranchin, Yunzhen yao, Maxime Peyrard, Chris Wendler, Michael Gastpar, Robert West, 24 Oct 2025, zip2zip: Inference-Time Adaptive Tokenization via Online Compression, https://arxiv.org/abs/2506.01084
- Hongyi Zhou, Weiran Liao, Xi Huang, Yucheng Tang, Fabian Otto, Xiaogang Jia, Xinkai Jiang, Simon Hilber, Ge Li, Qian Wang, \"Omer Erdin\c{c} Ya\u{g}murlu, Nils Blank, Moritz Reuss, Rudolf Lioutikov, 24 Oct 2025, BEAST: Efficient Tokenization of B-Splines Encoded Action Sequences for Imitation Learning, https://arxiv.org/abs/2506.06072
- Gabriel Maldonado, Narges Rashvand, Armin Danesh Pazho, Ghazal Alinezhad Noghre, Vinit Katariya, Hamed Tabkhi, 23 Sep 2025, Adversarially-Refined VQ-GAN with Dense Motion Tokenization for Spatio-Temporal Heatmaps, https://arxiv.org/abs/2509.19252
- Zeyu Liu, Zanlin Ni, Yeguo Hua, Xin Deng, Xiao Ma, Cheng Zhong, Gao Huang, 30 Sep 2025, CODA: Repurposing Continuous VAEs for Discrete Tokenization, https://arxiv.org/abs/2503.17760
- Dave Salvator, March 17, 2025, Explaining Tokens — the Language and Currency of AI: Tokens are units of data processed by AI models during training and inference, enabling prediction, generation and reasoning, https://blogs.nvidia.com/blog/ai-tokens-explained/
- Jiawei Xu, Chia Xin Liang, Ziqian Bi, Xiaoming Li, Danyang Zhang, Zhenyu Yu, Dec 2025, A Comprehensive Survey on Large Language Models: From Pre-training to Autonomous Agents, https://www.researchgate.net/profile/Ziqian_Bi/publication/399059225_A_Comprehensive_Survey_on_Large_Language_Models_From_Pre-training_to_Autonomous_Agents/links/694c94a07e61d05b5312836f/A-Comprehensive-Survey-on-Large-Language-Models-From-Pre-training-to-Autonomous-Agents.pdf
{kind=link}
Vocabulary Size Research
Papers on vocabulary size and vocabulary-related issues:
- Finding the Optimal Vocabulary Size for Neural Machine Translation, Thamme Gowda and Jonathan May, Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3955–3964, November 16-20, 2020, PDF: https://aclanthology.org/2020.findings-emnlp.352.pdf
- Welin Chen, David Grangier, and Michael Auli. 2016. Strategies for training large vocabulary neural language models. In Proc. ACL. https://arxiv.org/abs/1512.04906
- S. Jean, K. Cho, R. Memisevic, and Y. Bengio. On using very large target vocabulary for neural machine translation. arXiv preprint arXiv:1412.2007, 2014, https://arxiv.org/abs/1412.2007
- Jonas Geiping, Tom Goldstein, Dec 2022, Cramming: Training a Language Model on a Single GPU in One Day, https://arxiv.org/abs/2212.14034, Code: https://github.com/JonasGeiping/cramming (Examines vocabulary size impact on training efficiency. Note: code uses deprecated nvFuser compiler.)
- Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. PaLM: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022. https://arxiv.org/abs/2204.02311 (Google Palm architecture used a 256k vocabulary with SentencePiece tokenizer.)
- Benjamin Minixhofer, Edoardo Maria Ponti, Ivan Vulić, 13 May 2024, Zero-Shot Tokenizer Transfer, https://arxiv.org/abs/2405.07883 (Overcoming the limitation that the tokenizer is fixed for the model, by training the tokenizer to embeddings mapping so as to use different tokenizers, including effective input token pruning reducing tokens in the input with a larger vocabulary.)
- Yoon Kim, Yacine Jernite, David A. Sontag, and Alexander M. Rush. 2016. Character-aware neural language models. In AAAI, pp. 2741–2749. AAAI Press, 2016, https://arxiv.org/abs/1508.06615
- David Spuler, March 2024, Chapter 27. Tokenizer and Vocabulary, Generative AI in C++: Coding Transformers and LLMs, https://www.amazon.com/dp/B0CXJKCWX9
- Nikolay Bogoychev, Pinzhen Chen, Barry Haddow, Alexandra Birch, June 20, 2024, The Ups and Downs of Large Language Model Inference, with Vocabulary Trimming by Language Heuristics, School of Informatics, University of Edinburgh, Proceedings of the Fifth Workshop on Insights from Negative Results in NLP, pages 148–153 https://aclanthology.org/2024.insights-1.17.pdf
- Chaofan Tao, Qian Liu, Longxu Dou, Niklas Muennighoff, Zhongwei Wan, Ping Luo, Min Lin, Ngai Wong, 18 Jul 2024, Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies, https://arxiv.org/abs/2407.13623
- J Hong, G Lee, J Cho, Accelerating Multilingual Language Model for Excessively Tokenized Languages, Findings of the Association for Computational Linguistics: ACL 2024, pages 11095–11111 August 11-16, 2024, https://arxiv.org/abs/2401.10660 https://aclanthology.org/2024.findings-acl.660/ https://aclanthology.org/2024.findings-acl.660.pdf
- HyoJung Han, Akiko Eriguchi, Haoran Xu, Hieu Hoang, Marine Carpuat, Huda Khayrallah, 12 Oct 2024, Adapters for Altering LLM Vocabularies: What Languages Benefit the Most? https://arxiv.org/abs/2410.09644
- Yangyifan Xu, Jinliang Lu, Jiajun Zhang, 15 Apr 2024, Bridging the Gap between Different Vocabularies for LLM Ensemble, https://arxiv.org/abs/2404.09492 (Addressing the particular problem with two LLMs have been trained on different vocabularies, but must be used together in an ensemble architecture.)
- Matthew Durward and Christopher Thomson, 2024, Evaluating Vocabulary Usage in LLMs, Proceedings of the 19th Workshop on Innovative Use of NLP for Building Educational Applications, pages 266–282, June 20, 2024, https://aclanthology.org/2024.bea-1.22/ https://aclanthology.org/2024.bea-1.22.pdf
- Erik Wijmans, Brody Huval, Alexander Hertzberg, Vladlen Koltun, Philipp Krähenbühl, 13 Nov 2024, Cut Your Losses in Large-Vocabulary Language Models, https://arxiv.org/abs/2411.09009 https://github.com/apple/ml-cross-entropy
- Leonidas Gee, Andrea Zugarini, Leonardo Rigutini, Paolo Torroni, 15 Feb 2024, Fast Vocabulary Transfer for Language Model Compression, https://arxiv.org/abs/2402.09977
- Vilém Zouhar, 29 Jan 2024, Stolen Subwords: Importance of Vocabularies for Machine Translation Model Stealing, https://arxiv.org/abs/2401.16055
- Tobias Domhan, Eva Hasler, Ke Tran, Sony Trenous, Bill Byrne, Felix Hieber, July 2022, The Devil is in the Details: On the Pitfalls of Vocabulary Selection in Neural Machine Translation, Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, United States, https://aclanthology.org/2022.naacl-main.136/ https://aclanthology.org/2022.naacl-main.136.pdf
- Yuta Nozaki, Dai Nakashima, Ryo Sato, Naoki Asaba, Shintaro Kawamura, Efficient Vocabulary Reduction for Small Language Models, Jan 2025, Proceedings of the 31st International Conference on Computational Linguistics: Industry Track, pages 771–783, January 19–24, 2025, Association for Computational Linguistic, https://aclanthology.org/2025.coling-industry.64.pdf
- M Williams, N Aletras, 2025, Vocabulary-level Memory Efficiency for Language Model Fine-tuning, 10th Workshop on Representation Learning for NLP, https://aclanthology.org/anthology-files/pdf/repl4nlp/2025.repl4nlp-1.pdf#page=193
- Pengfei Cai, Yan Song, Qing Gu, Nan Jiang, Haoyu Song, Ian McLoughlin, 22 Jul 2025, Detect Any Sound: Open-Vocabulary Sound Event Detection with Multi-Modal Queries, https://arxiv.org/abs/2507.16343
- Atharv Goel, Mehar Khurana, 6 Jul 2025, Just Add Geometry: Gradient-Free Open-Vocabulary 3D Detection Without Human-in-the-Loop, https://arxiv.org/abs/2507.13363
- Kai Cheng, Zhengyuan Li, Xingpeng Sun, Byung-Cheol Min, Amrit Singh Bedi, Aniket Bera, 8 Aug 2025, EfficientEQA: An Efficient Approach to Open-Vocabulary Embodied Question Answering, https://arxiv.org/abs/2410.20263
- Drandreb Earl O. Juanico, Rowel O. Atienza, Jeffrey Kenneth Go, 26 Jul 2025, Interpretable Open-Vocabulary Referring Object Detection with Reverse Contrast Attention, https://arxiv.org/abs/2507.19891
- Yasser Benigmim, Mohammad Fahes, Tuan-Hung Vu, Andrei Bursuc, Raoul de Charette, 30 Jul 2025, FLOSS: Free Lunch in Open-vocabulary Semantic Segmentation, https://arxiv.org/abs/2504.10487
- Ramchalam Kinattinkara Ramakrishnan, Zhaocong Yuan, Shaojie Zhuo, Chen Feng, Yicheng Lin, Chenzheng Su, Xiaopeng Zhang, 31 Jul 2025, OmniDraft: A Cross-vocabulary, Online Adaptive Drafter for On-device Speculative Decoding, https://arxiv.org/abs/2507.02659
- Luca Barsellotti, Lorenzo Bianchi, Nicola Messina, Fabio Carrara, Marcella Cornia, Lorenzo Baraldi, Fabrizio Falchi, Rita Cucchiara, 5 Aug 2025, Talking to DINO: Bridging Self-Supervised Vision Backbones with Language for Open-Vocabulary Segmentation, https://arxiv.org/abs/2411.19331
- Junjie Wang, Keyu Chen, Yulin Li, Bin Chen, Hengshuang Zhao, Xiaojuan Qi, Zhuotao Tian, 15 Aug 2025, Generalized Decoupled Learning for Enhancing Open-Vocabulary Dense Perception, https://arxiv.org/abs/2508.11256
- Hanling Zhang, Yayu Zhou, Tongcheng Fang, Zhihang Yuan, Guohao Dai, Yu Wang, 21 Aug 2025, VocabTailor: Dynamic Vocabulary Selection for Downstream Tasks in Small Language Models, https://arxiv.org/abs/2508.15229
- Woojin Chung, Jeonghoon Kim, 21 Aug 2025, Exploiting Vocabulary Frequency Imbalance in Language Model Pre-training, https://arxiv.org/abs/2508.15390
- Zhixiang Chi, Yanan Wu, Li Gu, Huan Liu, Ziqiang Wang, Yang Zhang, Yang Wang, Konstantinos N. Plataniotis, 27 Aug 2025, Plug-in Feedback Self-adaptive Attention in CLIP for Training-free Open-Vocabulary Segmentation, https://arxiv.org/abs/2508.20265
- Wooseok Shin, Jisu Kang, Hyeonki Jeong, Jin Sob Kim, Sung Won Han, 7 Sep 2025, Leveraging Out-of-Distribution Unlabeled Images: Semi-Supervised Semantic Segmentation with an Open-Vocabulary Model, https://arxiv.org/abs/2507.03302
- Bingyu Li, Haocheng Dong, Da Zhang, Zhiyuan Zhao, Junyu Gao, Xuelong Li, 15 Sep 2025, Exploring Efficient Open-Vocabulary Segmentation in the Remote Sensing, https://arxiv.org/abs/2509.12040
- Yang Zhou, Shiyu Zhao, Yuxiao Chen, Zhenting Wang, Can Jin, Dimitris N. Metaxas, 10 Sep 2025, LED: LLM Enhanced Open-Vocabulary Object Detection without Human Curated Data Generation, https://arxiv.org/abs/2503.13794
- Weijia Dou, Xu Zhang, Yi Bin, Jian Liu, Bo Peng, Guoqing Wang, Yang Yang, and Heng Tao Shen, 2 Oct 2025, GeoPurify: A Data-Efficient Geometric Distillation Framework for Open-Vocabulary 3D Segmentation, https://arxiv.org/abs/2510.02186
- Nuowei Liu, Jiahao Kuang, Yanting Liu, Tao Ji, Changzhi Sun, Man Lan, Yuanbin Wu, 14 Oct 2025, Protein Design with Dynamic Protein Vocabulary, https://arxiv.org/abs/2505.18966
- Haotian Zhou, Xiaole Wang, He Li, Fusheng Sun, Shengyu Guo, Guolei Qi, Jianghuan Xu and Huijing Zhao, 28 Oct 2025, LagMemo: Language 3D Gaussian Splatting Memory for Multi-modal Open-vocabulary Multi-goal Visual Navigation, https://arxiv.org/abs/2510.24118
- Bingyu Li, Feiyu Wang, Da Zhang, Zhiyuan Zhao, Junyu Gao, Xuelong Li, 23 Oct 2025, MARIS: Marine Open-Vocabulary Instance Segmentation with Geometric Enhancement and Semantic Alignment, https://arxiv.org/abs/2510.15398
- Jes\'us Ortega-Peimbert, Finn Lukas Busch, Timon Homberger, Quantao Yang, and Olov Andersson, 18 Oct 2025, DIV-Nav: Open-Vocabulary Spatial Relationships for Multi-Object Navigation, https://arxiv.org/abs/2510.16518
- Wei Du, Nuowei Liu, Jie Wang, Jiahao Kuang, Tao Ji, Xiaoling Wang, Yuanbin Wu, 20 Oct 2025, DVAGen: Dynamic Vocabulary Augmented Generation, https://arxiv.org/abs/2510.17115
- Xi Zhu, Haochen Xue, Ziwei Zhao, Wujiang Xu, Jingyuan Huang, Minghao Guo, Qifan Wang, Kaixiong Zhou, Imran Razzak, Yongfeng Zhang, 20 Oct 2025, LLM as GNN: Graph Vocabulary Learning for Text-Attributed Graph Foundation Models, https://arxiv.org/abs/2503.03313
- Chiara Cappellino, Gianluca Mancusi, Matteo Mosconi, Angelo Porrello, Simone Calderara, Rita Cucchiara, 20 Oct 2025, DitHub: A Modular Framework for Incremental Open-Vocabulary Object Detection, https://arxiv.org/abs/2503.09271
- Atsuki Yamaguchi, Aline Villavicencio, Nikolaos Aletras, 27 Oct 2025, How Can We Effectively Expand the Vocabulary of LLMs with 0.01GB of Target Language Text?, https://arxiv.org/abs/2406.11477
- Yi Wang, Zeyu Xue, Mujie Liu, Tongqin Zhang, Yan Hu, Zhou Zhao, Chenguang Yang and Zhenyu Lu, 27 Oct 2025, Open-Vocabulary Spatio-Temporal Scene Graph for Robot Perception and Teleoperation Planning, https://arxiv.org/abs/2509.23107
- Chi Yan and Dan Xu, 8 Oct 2025, Progressive Gaussian Transformer with Anisotropy-aware Sampling for Open Vocabulary Occupancy Prediction, https://arxiv.org/abs/2510.04759
- Bilal Faye, Hanane Azzag, Mustapha Lebbah, 25 Sep 2025, Lightweight Modular Parameter-Efficient Tuning for Open-Vocabulary Object Detection, https://arxiv.org/abs/2408.10787
- Mohamad Amin Mirzaei, Pantea Amoie, Ali Ekhterachian, Matin Mirzababaei, 29 Sep 2025, CORE-3D: Context-aware Open-vocabulary Retrieval by Embeddings in 3D, https://arxiv.org/abs/2509.24528
- Raghavv Goel, Sudhanshu Agrawal, Mukul Gagrani, Junyoung Park, Yifan Zao, He Zhang, Tian Liu, Yiping Yang, Xin Yuan, Jiuyan Lu, Chris Lott, Mingu Lee, 28 Jun 2025, VOCABTRIM: Vocabulary Pruning for Efficient Speculative Decoding in LLMs, https://arxiv.org/abs/2506.22694
- Xiaomeng Fan, Yuchuan Mao, Zhi Gao, Yuwei Wu, Jin Chen, Yunde Jia, 6 Oct 2025, Beyond the Seen: Bounded Distribution Estimation for Open-Vocabulary Learning, https://arxiv.org/abs/2510.04770
- Haeji Jung, Jinju Kim, Kyungjin Kim, Youjeong Roh, David R. Mortensen, 12 Oct 2025, Happiness is Sharing a Vocabulary: A Study of Transliteration Methods, https://arxiv.org/abs/2510.10827
- Isabel Papadimitriou and Jacob Prince, 8 Oct 2025, Vocabulary embeddings organize linguistic structure early in language model training, https://arxiv.org/abs/2510.07613
- Daiki Chijiwa, Taku Hasegawa, Kyosuke Nishida, Shin'ya Yamaguchi, Tomoya Ohba, Tamao Sakao, Susumu Takeuchi, 9 Oct 2025, Lossless Vocabulary Reduction for Auto-Regressive Language Models, https://arxiv.org/abs/2510.08102
- Jiarui Hai, Helin Wang, Weizhe Guo, Mounya Elhilali, 23 Sep 2025, FlexSED: Towards Open-Vocabulary Sound Event Detection, https://arxiv.org/abs/2509.18606
- Ke Li, Di Wang, Ting Wang, Fuyu Dong, Yiming Zhang, Luyao Zhang, Xiangyu Wang, Shaofeng Li, Quan Wang, 23 Sep 2025, RSVG-ZeroOV: Exploring a Training-Free Framework for Zero-Shot Open-Vocabulary Visual Grounding in Remote Sensing Images, https://arxiv.org/abs/2509.18711
- Rashina Hoda, 22 Oct 2025, Toward Agentic Software Engineering Beyond Code: Framing Vision, Values, and Vocabulary, https://arxiv.org/abs/2510.19692
- Jiahang Tu, Qian Feng, Jiahua Dong, Hanbin Zhao, Chao Zhang, Nicu Sebe, Hui Qian, 30 Sep 2025, CE-SDWV: Effective and Efficient Concept Erasure for Text-to-Image Diffusion Models via a Semantic-Driven Word Vocabulary, https://arxiv.org/abs/2501.15562
- Jinbin Zhang, Nasib Ullah, Erik Schultheis, Rohit Babbar, 11 Oct 2025, DynaSpec: Context-aware Dynamic Speculative Sampling for Large-Vocabulary Language Models, https://arxiv.org/abs/2510.13847
Tokenization for Machine Vision
Tokenization for images and machine vision is different from text analysis:
- Shengju Qian; Yi Zhu; Wenbo Li; Mu Li; Jiaya Jia, What Makes for Good Tokenizers in Vision Transformer? 22 December 2022, IEEE Transactions on Pattern Analysis and Machine Intelligence, pp.1 - 13, https://arxiv.org/abs/2212.11115
- T. Xiao, M. Singh, E. Mintun, T. Darrell, P. Dollar, and R. Girshick, ´ “Early convolutions help transformers see better,” in NeurIPS, 2021, https://arxiv.org/abs/2106.14881
- L. Yuan, Y. Chen, T. Wang, W. Yu, Y. Shi, Z. Jiang, F. E. Tay, J. Feng, and S. Yan, “Tokens-to-token vit: Training vision transformers from scratch on imagenet,” in ICCV, 2021, https://arxiv.org/abs/2101.11986
- X. Chen, S. Xie, and K. He, “An empirical study of training self-supervised visual transformers,” in ICCV, 2021, https://arxiv.org/abs/2104.02057
- C.-F. Chen, Q. Fan, and R. Panda, “Crossvit: Cross-attention multi-scale vision transformer for image classification,” arXiv preprint arXiv:2103.14899, 2021, https://arxiv.org/abs/2103.14899
- W. Wang, E. Xie, X. Li, D.-P. Fan, K. Song, D. Liang, T. Lu, P. Luo, and L. Shao, “Pvtv2: Improved baselines with pyramid vision transformer,” arXiv preprint arXiv:2106.13797, 2021, https://arxiv.org/abs/2106.13797
- T. Wang, L. Yuan, Y. Chen, J. Feng, and S. Yan, “Pnp-detr: Towards efficient visual analysis with transformers,” in ICCV, 2021, https://arxiv.org/abs/2109.07036
- M. S. Ryoo, A. Piergiovanni, A. Arnab, M. Dehghani, and A. Angelova, “Tokenlearner: What can 8 learned tokens do for images and videos?” in NeurIPS, 2021, https://arxiv.org/abs/2106.11297
- X. Yue, S. Sun, Z. Kuang, M. Wei, P. Torr, W. Zhang, and D. Lin, “Vision transformer with progressive sampling,” in ICCV, 2021, https://arxiv.org/abs/2108.01684
- Z. Jiang, Q. Hou, L. Yuan, D. Zhou, Y. Shi, X. Jin, A. Wang, and J. Feng, “All tokens matter: Token labeling for training better vision transformers,” in NeurIPS, 2021, https://arxiv.org/abs/2104.10858
- Shenghao Xie, Wenqiang Zu, Mingyang Zhao, Duo Su, Shilong Liu, Ruohua Shi, Guoqi Li, Shanghang Zhang, Lei Ma, 30 Oct 2024 (v2), Towards Unifying Understanding and Generation in the Era of Vision Foundation Models: A Survey from the Autoregression Perspective, https://arxiv.org/abs/2410.22217 https://github.com/EmmaSRH/ARVFM
- Sebastian Raschka, Nov 03, 2024, Understanding Multimodal LLMs: An introduction to the main techniques and latest models, https://magazine.sebastianraschka.com/p/understanding-multimodal-llms
Semantic Tokenization
Papers on semantic tokenization, such as identifying the part-of-speed of a word:
- Kristina Toutanova, Dan Klein, Christopher D. Manning, and Yoram Singer. 2003. Feature-rich part-of-speech tagging with a cyclic dependency network. In NAACL 3, pages 252–259, https://dl.acm.org/doi/10.3115/1073445.1073478
- Marie-Catherine de Marneffe, Bill MacCartney, and Christopher D. Manning. 2006. Generating typed dependency parses from phrase structure parses. In LREC 2006, pages 449–454, PDF: http://www.lrec-conf.org/proceedings/lrec2006/pdf/440_pdf.pdf
Tokenization of Non-English Languages
Various non-English double-byte languages cause extra difficulties in tokenization:
- Chenglei Si, Zhengyan Zhang, Yingfa Chen, Fanchao Qi, Xiaozhi Wang, Zhiyuan Liu, Yasheng Wang, Qun Liu, Maosong Sun, "Sub-Character Tokenization for Chinese Pretrained Language Models", Transactions of the Association for Computational Linguistics, vol.11, pp.469, 2023, https://arxiv.org/abs/2106.00400, Code: https://github.com/thunlp/SubCharTokenization
- Jonathan J. Webster and Chunyu Kit. 1992. Tokenization as the initial phase in NLP. In COLING 1992 Volume 4: The 14th International Conference on Computational Linguistics, https://dl.acm.org/doi/10.3115/992424.992434, DOI: https://doi.org/10.3115/992424.992434
- N. Venkatesan, N. Arulanand, "Implications of Tokenizers in BERT Model for Low-Resource Indian Language", Journal of Soft Computing Paradigm, vol.4, no.4, pp.264, 2023, https://irojournals.com/jscp/article/view/4/4/5
- Cagri Toraman, Eyup Halit Yilmaz, Furkan Şahi̇nuç, Oguzhan Ozcelik, "Impact of Tokenization on Language Models: An Analysis for Turkish", ACM Transactions on Asian and Low-Resource Language Information Processing, vol.22, no.4, pp.1, 2023, https://arxiv.org/abs/2204.08832
- Sumalatha Bandari, Vishnu Vardhan Bulusu, BERT Tokenization and Hybrid-Optimized Deep Recurrent Neural Network for Hindi Document Summarization January 2022, International Journal of Fuzzy System Applications 11(1):1-28, DOI:10.4018/IJFSA.313601, http://dx.doi.org/10.4018/IJFSA.313601
More Research
Read more about:
AI Books from Aussie AI

|
The Sweetest Lesson: Your Brain Versus AI: new book on AI intelligence theory:
Get your copy from Amazon: The Sweetest Lesson |

|
RAG Optimization: Accurate and Efficient LLM Applications:
new book on RAG architectures:
Get your copy from Amazon: RAG Optimization |

|
Generative AI Applications book:
Get your copy from Amazon: Generative AI Applications |

|
Generative AI programming book:
Get your copy from Amazon: Generative AI in C++ |

|
CUDA C++ Optimization book:
Get your copy from Amazon: CUDA C++ Optimization |

|
CUDA C++ Debugging book:
Get your copy from Amazon: CUDA C++ Debugging |